Introduction
Background
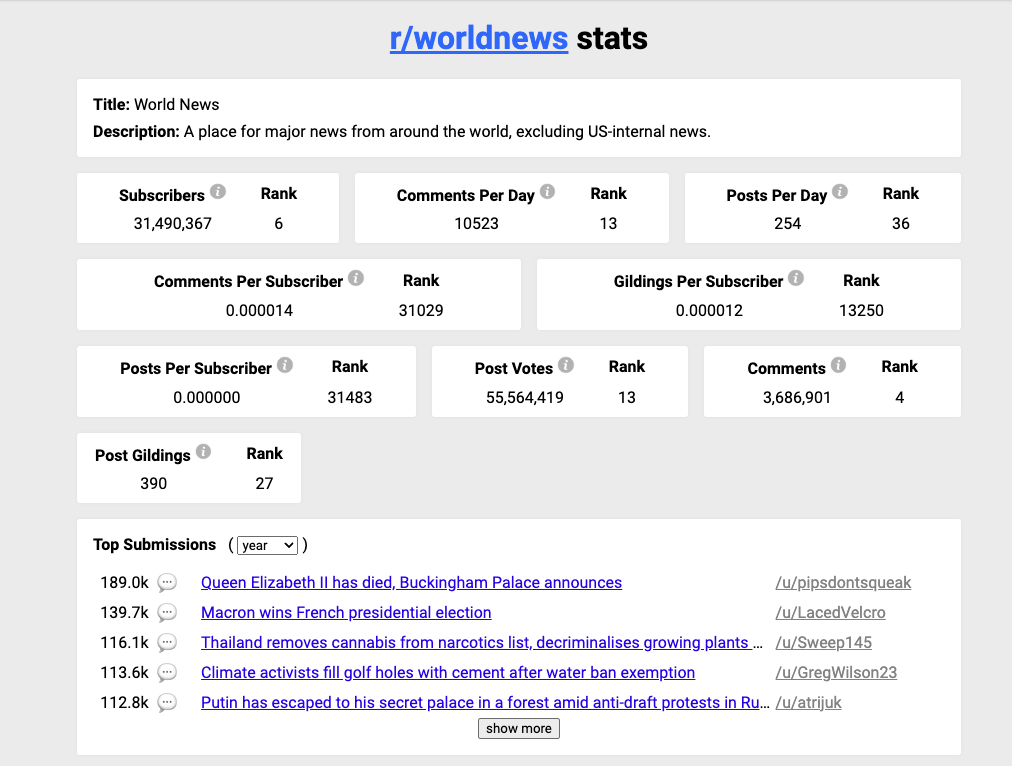
This project is based on the Push Shift Reddit Dataset and its related work which has served as the primary source for our data and has explanations for our variable’s meanings. The original data contains posts from all subreddits between June 2005 and April 2019, but for the purposes of our project we have restricted ourselves to the r/worldnews subreddit between January, 2022 and January 2023. It is one of the most active and subscribed subreddits on the website, with nearly 31.5 million subscribers as of April 2023. The subreddit was formed in January of 2008, and in its current form is a combination of discussion threads and posts which contain news stories, which can be seen in the screenshot below.
Figure 1.1 : A Quick Glance at r/worldnews Subreddit
Each submission to the subreddit consists of the article title and a link to the material for users to examine after which they can return to reddit to share their thoughts on that particular news story. Unlike other prominent news and politics subreddits, r/worldnews is less America-centric in coverage and has a user base with greater ideological diversity. For this reason, it was selected to analyze the behavior of news consumers and the sorts of news products that are most successful in this supposedly neutral environment. The subreddit data we used consisted of 18,548,934 comments across 170,144 submissions, which is visualized in the figure below. It should be noted that upon analysis some temporal gaps in the data were found.
We also incorporated other data sources to expand our analysis, namely data from Armed Conflict Location & Event Data Project (ACLED) and Google Trends. Using these we sought to examine the timeline of the Russia-Ukraine Conflict, which dominated the topics of the submissions. These datasets, we believe, allow us to better represent the events on the ground and media production, as opposed to the media consumption occurring within the subreddit.
Without going into the specific methods used, we also wish to highlight this project was accomplished using the Amazon Web Services(AWS) platform to work with Spark, and that we used a combination of several different models to achieve our goals, most notably pretrained models from JohnSnowLabs and models which we trained with our data from VaderSentiment. All the code can be found in the GitHub link located on the banner below of each page.
About the Team
Lucienne L. Julian Sonali Subbu Rathinam Peijin Li Aaron Genin